奶酪对“语音识别”的研究,
最早是因为想把自己喜欢的视频文案保存起来。
视频内容不但占用空间大,想要全文索引,又或者要回溯查询时,都是一件非常困难的事。
将一个 20GB 的视频教程,压缩为 2MB 的文本内容。
这是以前不敢想像想象的事情。
然而现在,有了人工智能的加持,这一切都变得触手可及。
01
在线转录
国内最早免费开放在线语音转文字的应用,是网易见外。
不但是速度快,准确率还超出了人们的预期,真正做到了一键转录,被盛赞业界良心,然后没多久,它就下架了。
而现在接棒的是——飞书妙记。
1.1、飞书妙记
飞书妙记是抖音旗下产品,注册登陆后,就直接上传音频或者视频,即使不需要介绍,也一看就知道怎么用。
地址:
https://www.feishu.cn/product/minutes
1.2、使用测评
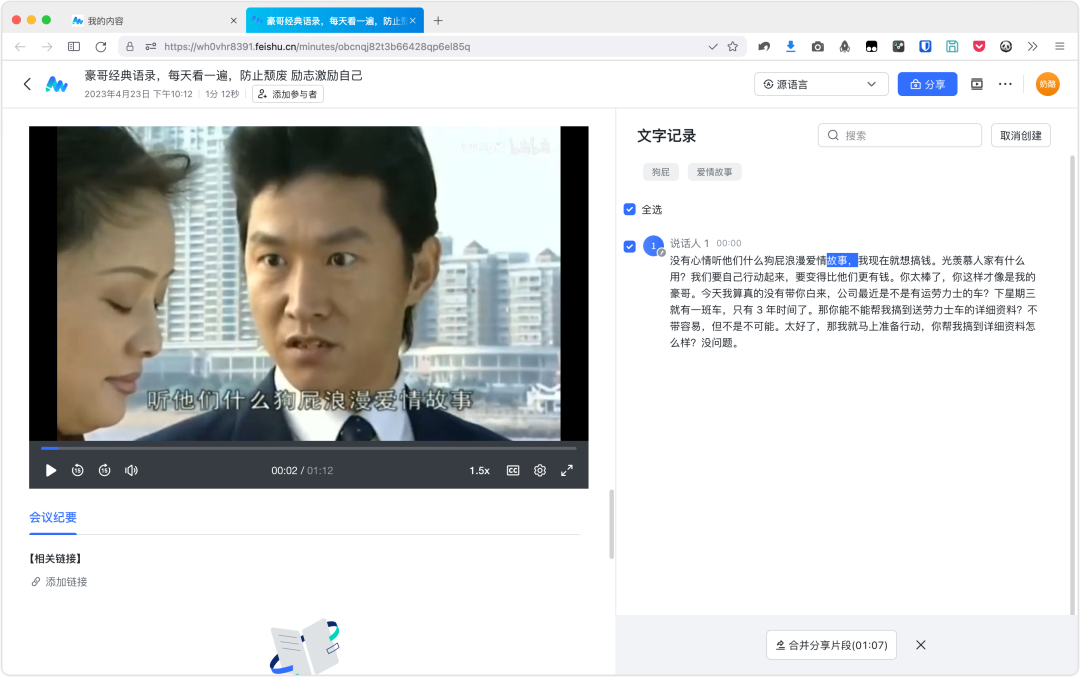
速度:快,10 分钟视频花费了 1分 25 秒分钟。
准确率:绝大部分内容都能正确识别,且能区分不同说话人。
特色功能:支持中、英、日 3 种语言,能自动添加标点符号和章节分段,支持免费导出为 TXT 和 SRT 格式。
1.3、同类产品
如果要说有什么缺点的话。那就飞书妙记免费用户的存储空间,从原来的 100G 变成 2G,一下子就寒酸了许多。
但和同类产品相比,飞书妙记仍然是更好的选择。
比如讯飞听见、钉钉闪记、阿里云、百度云等产品,它们要么免费额度少,要么需要申请 API,使用门槛高。
而飞书妙记以空间大小为度量。
你可以将视频转换为音频来缩小体积,又或者,你还可以通过删除已经转写的内容来释放空间。
换句话说,你还是可以无限白票。
02
软件转录
如果你需要转录的内容很多,又或者很长,那么使用桌面软件来操作会更加方便。
而在这个领域的佼佼者是 —— 剪映。
2.1、剪映
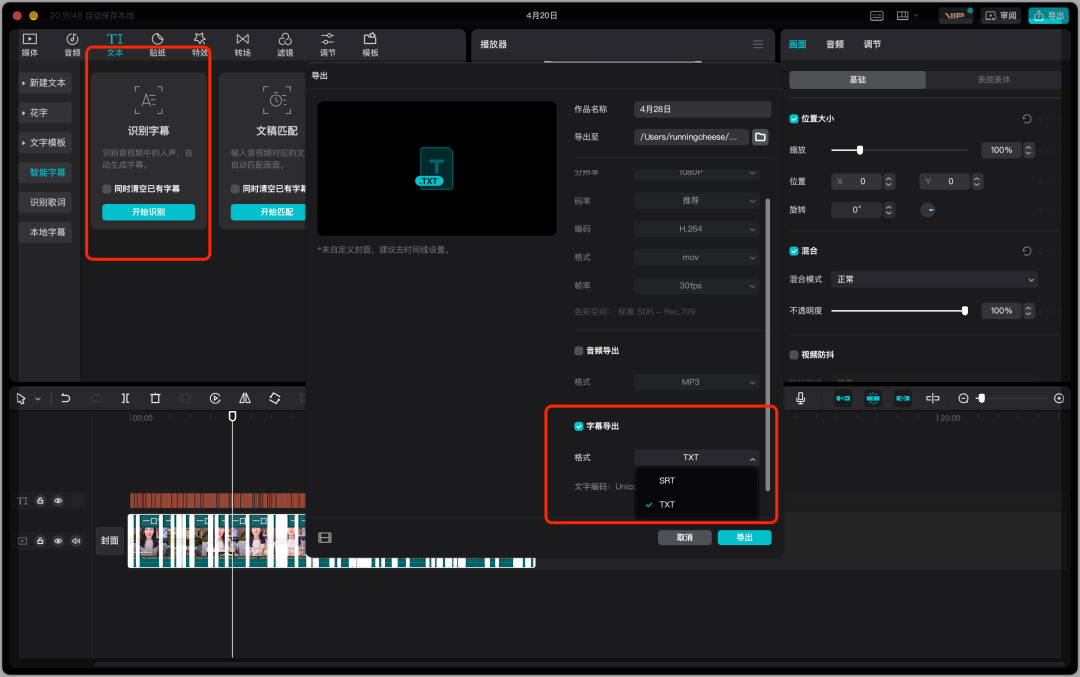
剪映也是是抖音旗下产品,它是一款桌面视频剪辑软件,但同时提供了识别语音功能,使用时需要联网使用。
使用方法也很简单,点击导航栏的“文本”,然后选择“智能字幕”,即可一键生成字幕。
地址:https://www.capcut.cn
2.2、使用测评
由于同样是字节系产品,剪映的准确率非常高,转录速度也非常的快,同样 10 分钟的视频,剪映只用了 32 秒。
而且,我们不用像“飞书妙记”那样担心空间不够用。
因为抖音不会担心自己的语音识别技术被白票,它担心的是没有人上传视频到抖音。
抖音推出剪映的目的,是为了降低用户制作视频门槛,让更多的人参与到视频制作来,抖音的收益在别处而已。
2.3、同类产品
目前国内能与剪映对标的,当属 B 站推出的“必剪”了。
它的产品逻辑一样,也是为了方便用户创作视频,然后上传到 B 站。
然而在免费额度上,必剪远不如剪映,必剪支持 15 分钟的音频转录,而剪映最大支持 2 小时且不限次数使用。
而且,剪映现在已经支持导出字幕,你可以将导出的字幕用在其它的软件上,抖音格局打开了。
应该说,剪映是视频创作者的必备。
03
离线转录
上面的两款应用都需要联网使用,如果你比较在意隐私的问题,那么你需要一款离线的语音识别工具。
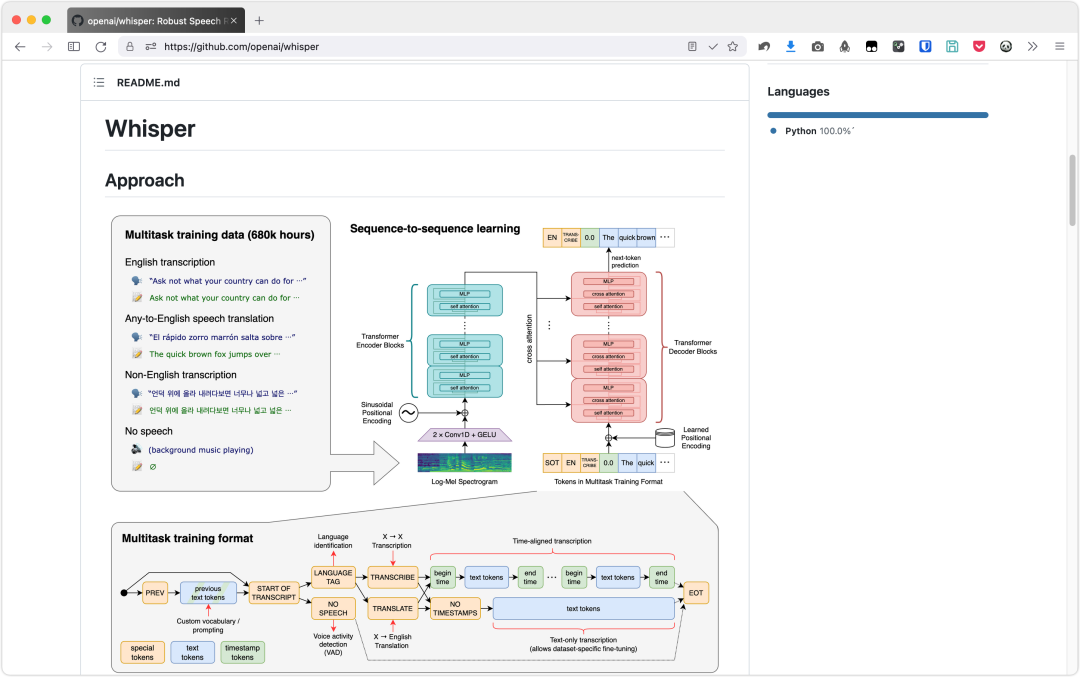
OpeanAI 推出的 Whipser 语音识别模型,是目前最好的选择,没有之一。
对,它和 ChatGPT 是同门师兄弟。
3.1、Whisper
Whipser 多语言语音识别模型,通过了 68 万小时的语音数据训练,支持 99 种语言,对英文的表现更是强无敌。
更重要的是,它开源免费,在电脑上你就能离线使用。
地址:
https://github.com/openai/whisper
在速度方面。
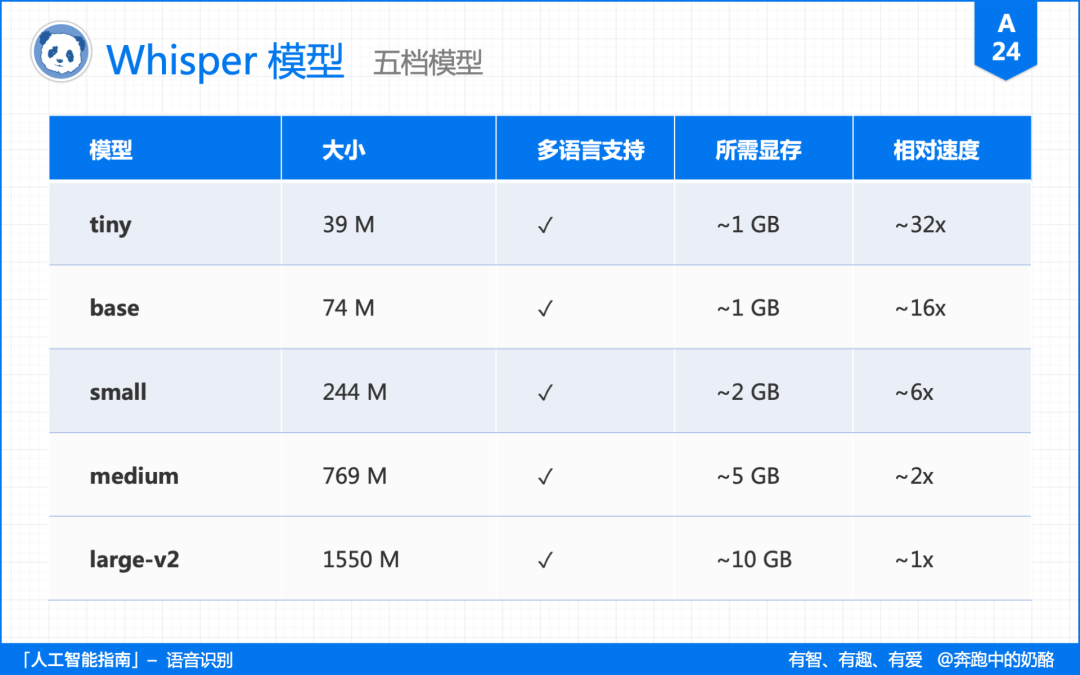
为应对不同的语音转录需求,Whipser 一共推出了 tiny、base、small、medium、large 五档模型。
转录效果依次增加,但相应消耗的时间也会增加。
在相同的硬件条件下,large 模型的耗时是 medium 的 2 倍,small 的 6 倍,base 的 16 倍,tiny 的 32 倍。
使用方法:
Whisper 官方使用 Python 开发,安装后,在文件所在目录打开终端,运行 whisper audio.mp3 即可进行转录。
想进行自定义设置,则可以在后面追加命令参数,具体包括:
whisper audio.mp3 –命令参数
–task
指定转录方式,默认使用 –task transcribe 转录模式,–task translate 则为翻译模式,目前只支持英文。
–model
指定使用模型,默认使用 –model small,Whisper 还有英文专用模型,就是在名称后加上 .en,这样速度更快。
–language
指定转录语言,默认会截取 30 秒来判断语种,但最好指定为某种语言,比如指定中文是 –language Chinese。
–device
指定硬件加速,默认使用 –device cuda ,也就是显卡,–device cpu 为 CPU, –device mps 为 M1 芯片。
3.2、WhisperDesktop
如果使用 Python 命令行的这种形式,槛太高,那么图形化软件 WhisperDesktop 会是一个好选择。
地址:
https://github.com/Const-me/Whisper
为了方便下载,我已经将 WhisperDesktop 和模型文件搬运到了国内的不限速网盘。
公众号后台回复关键字 A24 即可下载。
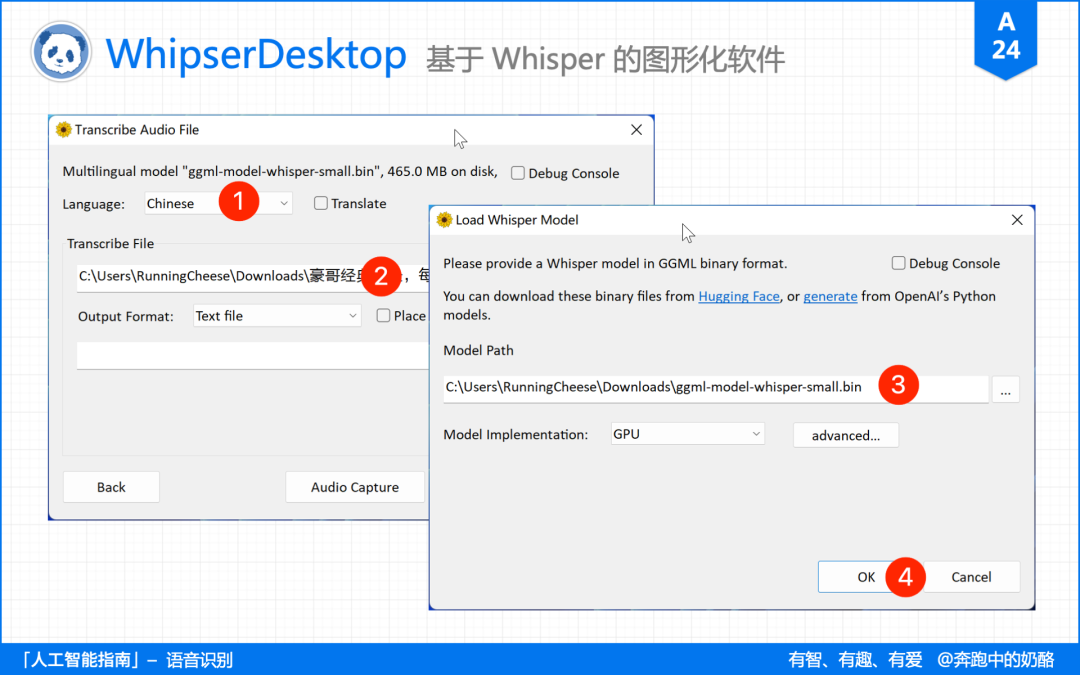
使用方法分为两步:下载软件 + 载入模型。
下载 WhisperDesktop 后,点击运行,然后加载模型文件,最后选择文件即可进行转录。
由于支持 GPU 硬解,转录速度也非常的快,我测试了一个 2 分钟的视频,使用 medium 模型,花费不到 20 秒。
PS:具体得看显卡性能。
3.3、Buzz
另一款基于 Whisper 的图形化软件是 Buzz,相比 WhipserDesktop,Buzz 支持 Windows、macOS、Linux。
地址:
https://github.com/chidiwilliams/buzz
为了方便下载,我也将 Buzz 和模型文件搬运到了国内的不限速网盘。
公众号后台回复关键字 A24 即可下载。
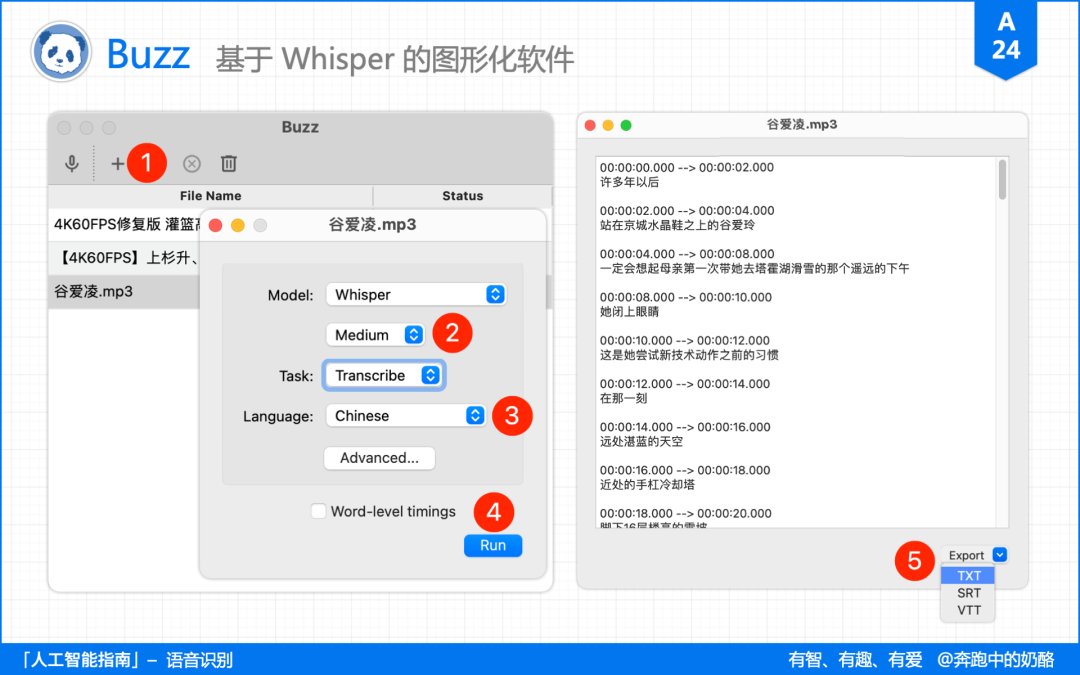
使用方法也是:安装软件 + 下载模型。
Buzz 的安装包体积稍大,同时 Buzz 使用的是 .pt 后缀名的模型文件,点击运行后会自动下载模型文件。
但你可以提前下好模型文件,然后放在指定的位置即可。
Windows:C:\Users\<你的用户名>\.cache\whisper Mac:~/.cache/whisper
由于 Buzz 使用的是 CPU 硬解,目前还不支持 GPU 硬解。
同样一个 2 分钟的视频,使用 medium 模型,耗时花费了 2 分 30 秒,比例大概 1:1.2,花费时间还是很长的。
3.4、使用测评
就准确性而言。
三款产品里,飞书妙记和剪映,在中文识别上的效果更好,大体与 Whipser 的 large 模型相当。
飞书妙记甚至还有标点符号、文章分段,智能纠错等功能,在测试中,飞书妙记是唯一个正确转录“谷爱凌”的。
原因是联网转录,通过“云词库”可以自动选择更符合上下文的同音词。
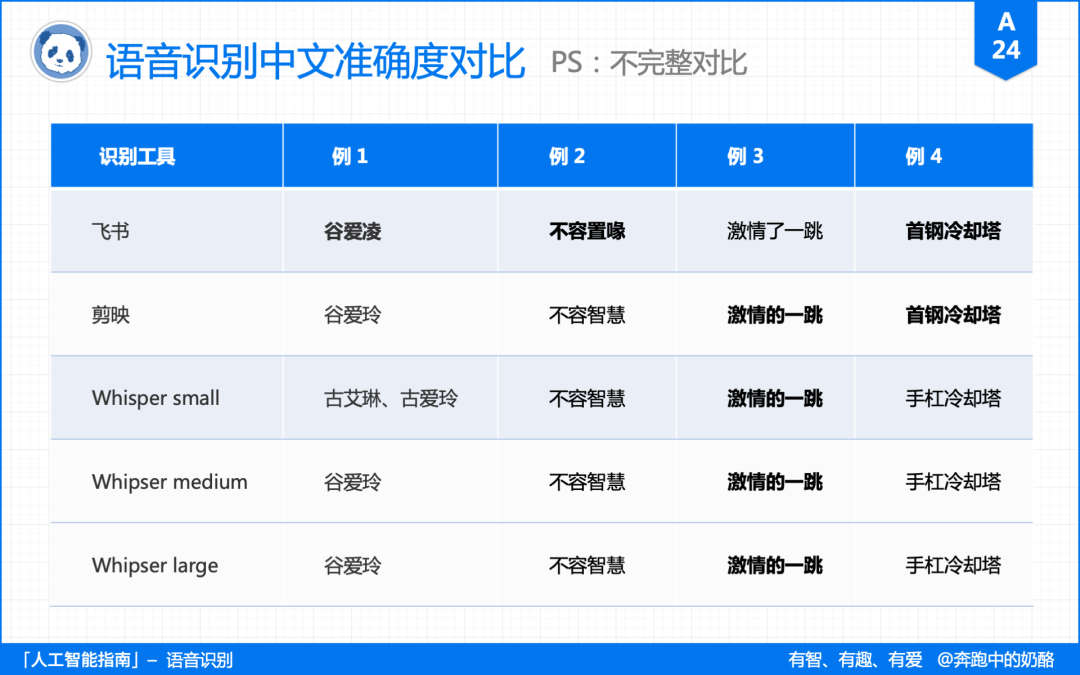
Whisper 的音频数据集只有 1/3 来自非英语,在准确性方面,Whisper 对英文的识别错误率为 4.2,中文为 14.7。
如果转录的音频是英文,那么用 samll 模型就能保证绝大多数正确。
而如果转录的音频是中文,那么至少要用到 medium 模型,才能保证绝大多数正确。
Whisper 强在多语言支持,还有超高的英语识别率。
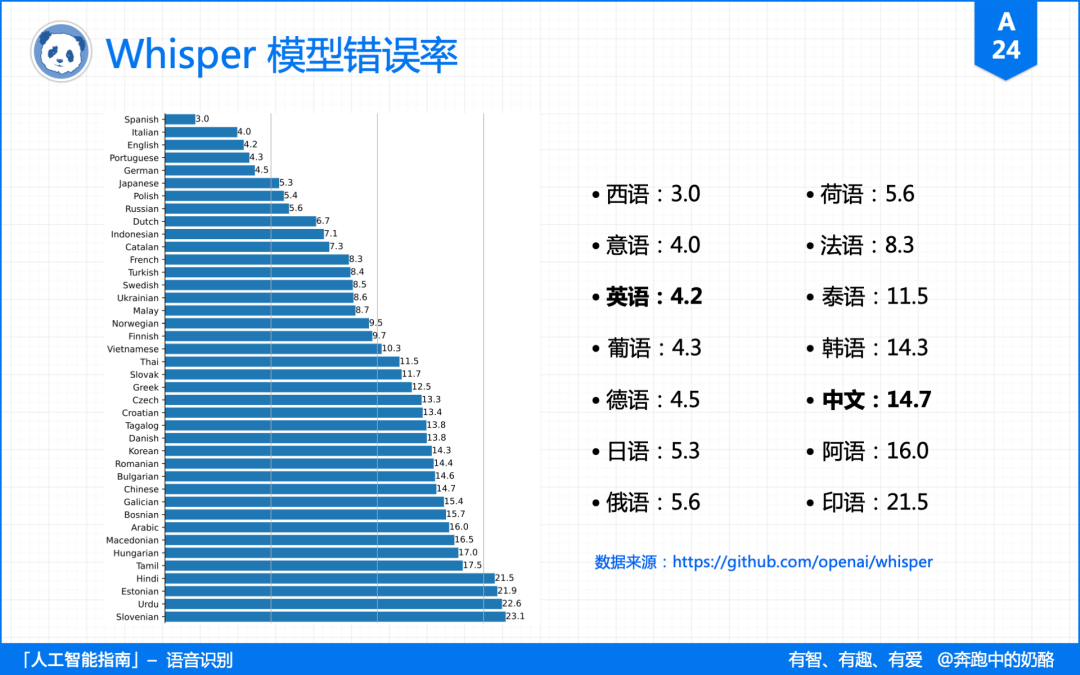
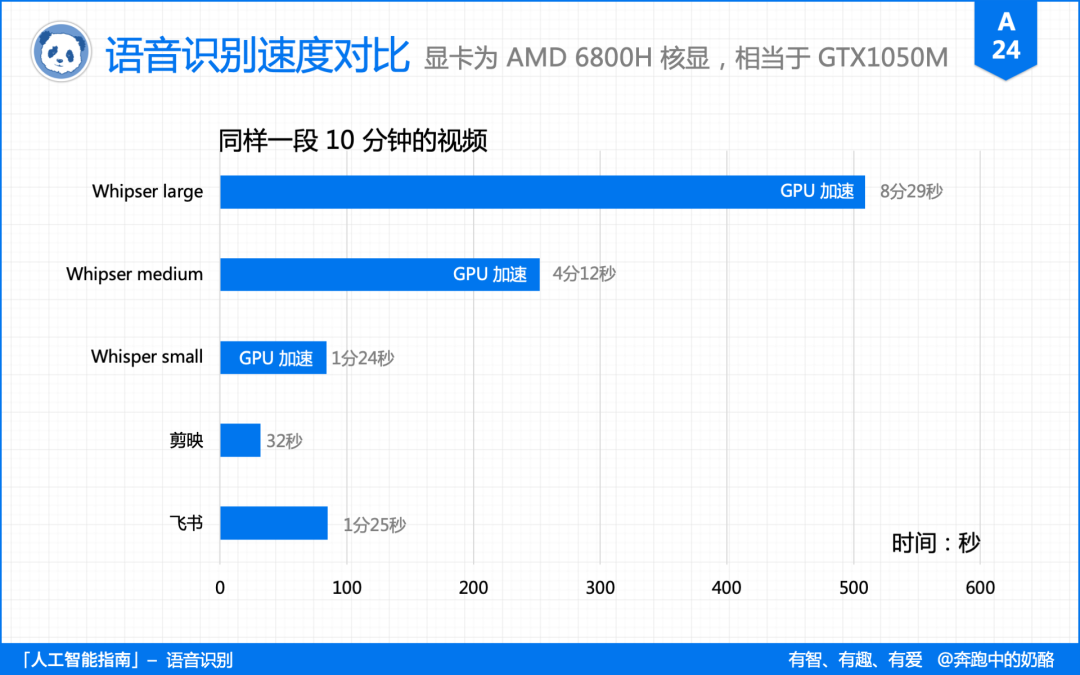
就转录速度而言。
飞书妙记和剪映都需要联网上传,其中剪映的速度最快,而 Whisper 的转录速度极度依赖显卡的加持。
下面是使用显卡加速,同一段 10 分钟视频的速度对比。
04
语音识别技巧
无论怎样,任何一款语音识别工具都没办法保证 100% 准确,我们还需要有一定的技巧。
4.1、纯净输入
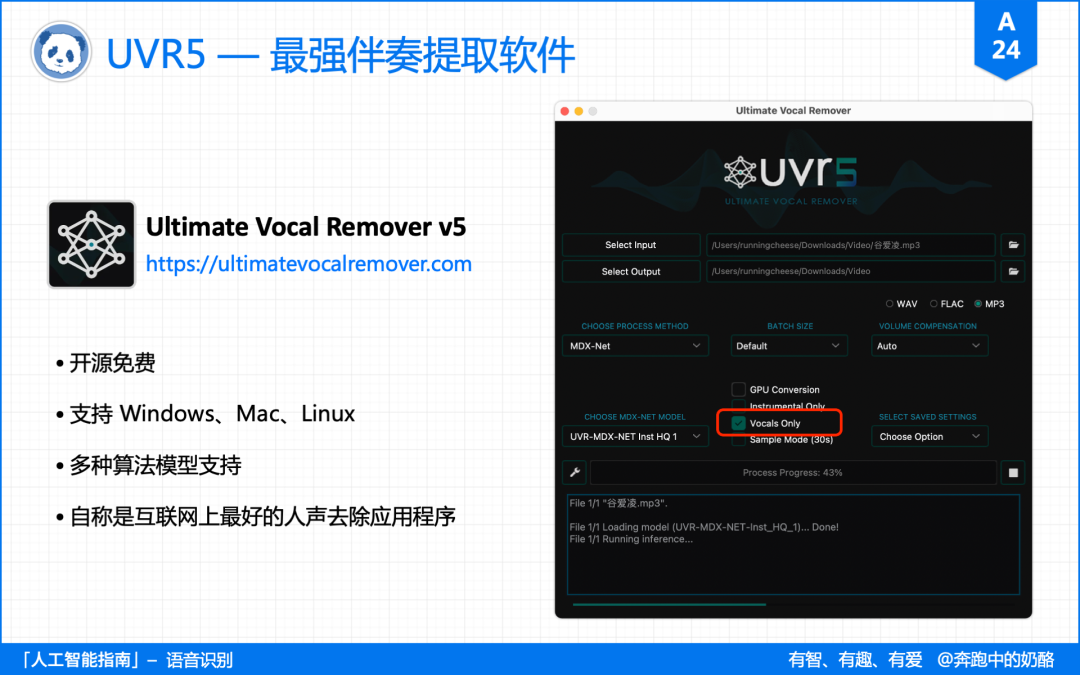
如果转录的是歌曲,又或者有嘈音,背景音乐太大,使用人声分离工具,突出人声,那么识别效果将大大提高。
这样的工具很多,可以选择在线应用,也可以选择免费开源的 UVR5。
在线应用:https://vocalremover.org
UVR5:https://ultimatevocalremover.com
4.2、字幕翻译
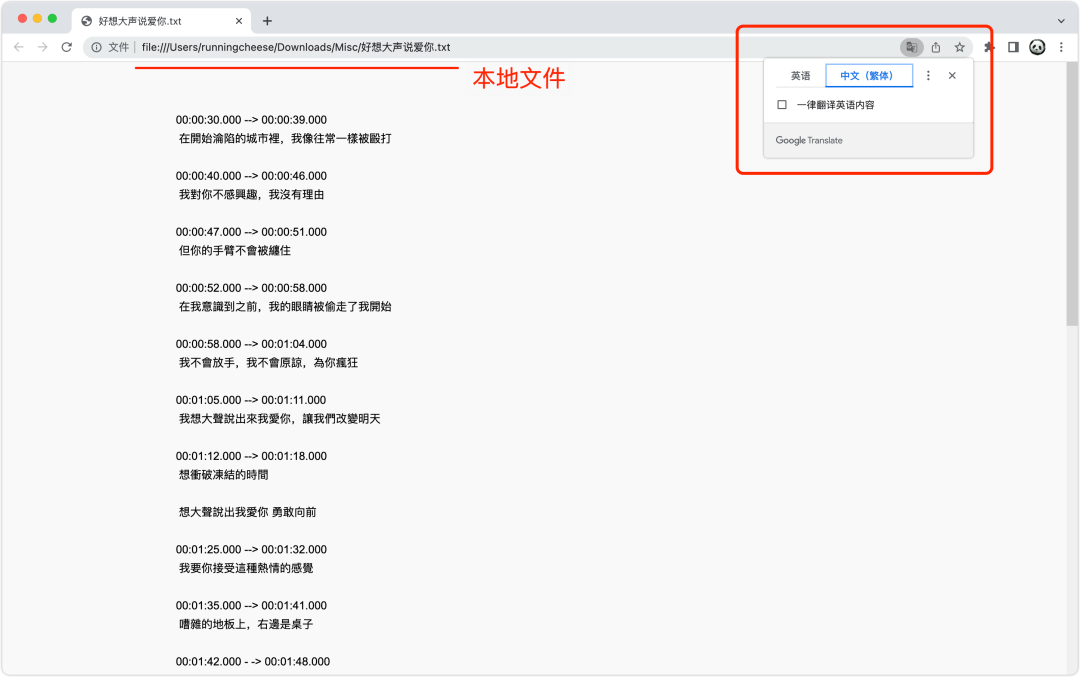
Whisper 有时转录出来的文本是繁体中文,又或者你想把字幕翻译为英语来做双语字幕。
一个简单的方法,就是将字幕文件在 Chrome 浏览器中打开,使用自带的翻译功能,即可一键翻译为想要的语言。
当然,你也可以用更加专业的字幕工具,比如 Subtitle Edit。
地址:
https://github.com/SubtitleEdit/subtitleedit
4.3、标点符号
除了飞书妙记外,其它工具都没有标点符号,而且也没有章节分段,如果你想把语音识别后的文本保存为文章。
一个简单的方法,是利用 ChatGPT 来重新排版,只需要提前输入提示词就可以了。
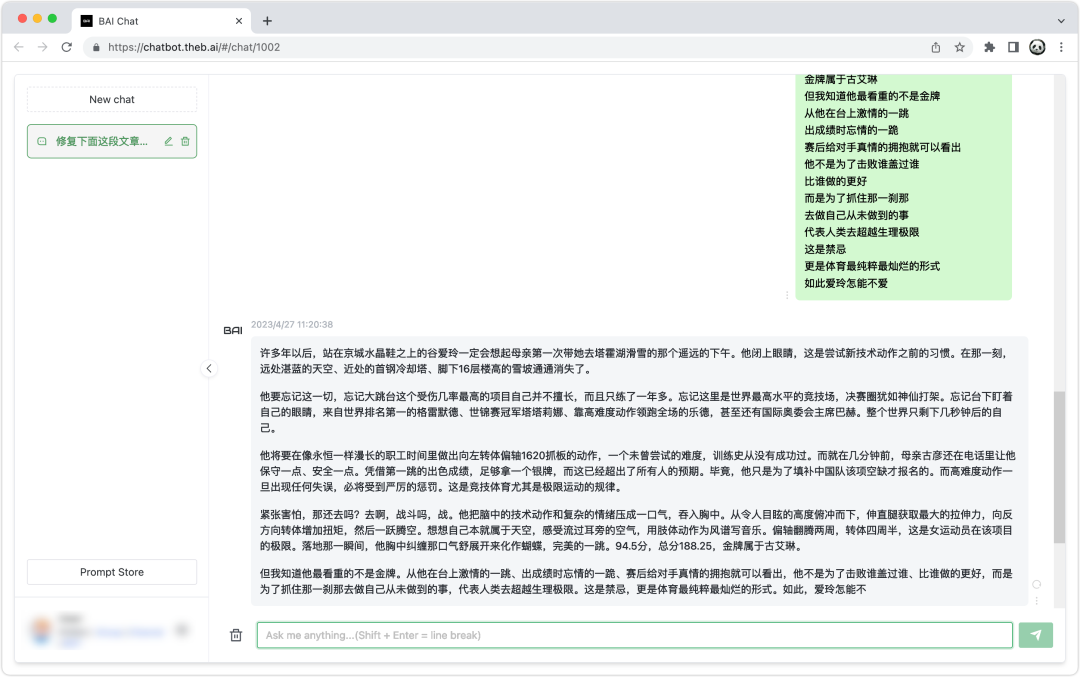
具体:“修复下面这段文章的标点符号并分成段落:<文本内容>”。
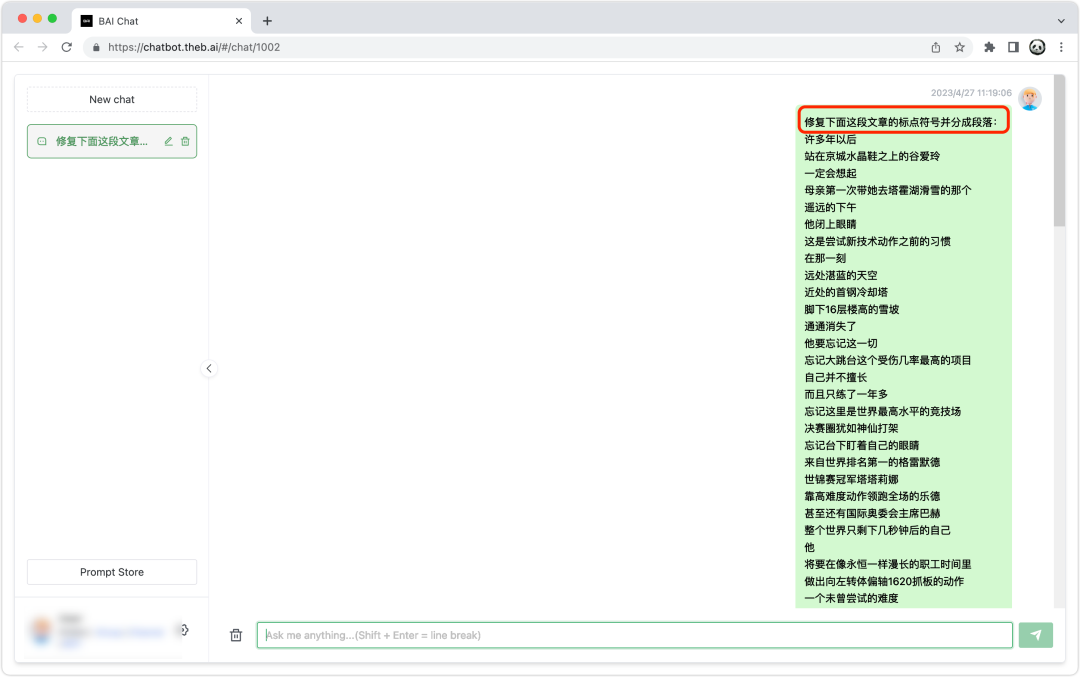
需要注意的是,GPT-3.5 输出的最大限制是 777 个字符,所以每一次输入最好不要超过 777 个中文。
但如果你用的是 GPT-4 的话,就没有这个限制。
4.4、一键转录
如果我有大量的视频转文字,和视频字幕生成需求,有没有办法一键转录?
有的!奶酪研究了一套方法,只需要一个 bat 文件即可一键转录,具体我们在下期《语音一键识别》中再做介绍。
4.5、实时转录
除了转录现有视频,有没有办法实时转录直播中的视频?
当然也有!我们同样可以利用 Whisper 来实现同声传译,具体我们在下下期《同声传译》中再做介绍。
结尾
2022 年末,OpenAI 发布的 Whisser 多语言语音识别模型,绝对算得上是一个“游戏改变者”。
在可以预见的未来。
首先,语音识别将会彻底免费,并成为一项公共服务。
其次,视频的语言屏障将会彻底打破,视频一键生成字幕,甚至自动生成字幕,已经成为现实。
还有,视频也将转向文字化,一个 20GB 的视频内容,可以压缩为 2MB 的文本内容,并且能被全文索引。
最后,Whisper 的入场,也会加速人工智能从单模态模型,向多模态模型的发展。
动动嘴皮就能拍出一部电影的魔幻场景,
也正在发生!
生活在“强人工智能”时代,实在是太幸福啦!












评论前必须登录!
立即登录 注册